Oltre i big data, cosa sono i thick data e in che modo ci cambieranno la vita

(GettyImages)

Comprendere i dati è divenuta una delle chiavi per raggiungere il successo. Ma che tipo di dati? Con quali metodi vanno raccolti? E perché in alcune occasioni le informazioni che cerchiamo non sono precise oppure sono del tutto errate? Semplicemente spesso i dati non sono stati interpretati nel modo corretto.
Piattaforme e servizi online hanno trascurato, negli anni, i Thick Data: la convinzione di possedere una grande mole di dati e di poterli mettere in relazione tra loro attraverso l’uso di tutte quelle tecnologie e metodologie di analisi di dati massivi, finalizzate ad estrapolarli e analizzarli (Big Data) ci ha illuso che bastasse disporne per conoscere – con certezza matematica – tutte le informazioni necessarie per prevedere fenomeni futuri. Cinque anni fa Lisa Arthur, in un articolo pubblicato su Forbes.com, li definiva come “una raccolta di dati provenienti da fonti tradizionali e digitali all’interno e all’esterno dell’azienda che rappresenta una fonte di continua scoperta e analisi”. Ma la domanda che ci poniamo oggi è: avere più informazioni possibili, senza conoscerne le dinamiche che hanno portato all’origine di un dato piuttosto che di un altro, può davvero essere d’aiuto?
L’esempio di Placa del Sol
Per comprendere davvero cosa sono i “Thick Data” e in che modo possono cambiare la nostra vita dobbiamo fare un passo indietro ad un anno fa e spostarci a Barcellona, precisamente a Placa del Sol, dove cittadini e turisti sono soliti intrattenersi, fino a notte inoltrata, nella celebre piazza della movida, nel quartiere di Barrio Gràcia, in cui si chiacchiera bevendo qualcosa. Un comportamento sociale del tutto normale che, tuttavia, disturbava il sonno dei residenti, costretti più e più volte a lamentarsi con l’amministrazione comunale, senza venirne a capo. Nel 2017 però, i founders del progetto “Making Sense” proposero alle famiglie del quartiere di istallare i sensori dello “Smart Citizen Kit”, almeno uno all’interno ed uno all’esterno dell’abitazione, così da poter monitorare costantemente i livelli di inquinamento acustico effettivo (quello generato in strada) con quello percepito nelle abitazioni in modo da confrontare i dati con le tabelle ufficiali.
Dopo non poche difficoltà nell’impiego di questa tecnologia, specie nel caricare i dati sulla piattaforma online per la comparazione, i cittadini hanno potuto verificare un dato di fatto che ben conoscevano: i livelli di inquinamento acustico erano ben oltre la soglia consentita dall’Organizzazione Mondiale della Sanità. I residenti sono così diventati autonomi nel monitorare l’inquinamento acustico mentre i ricercatori hanno compreso come rendere questa tecnologia alla portata di tutti per aumentare il livello di conoscenze tecnico-scientifiche dei cittadini. Inoltre, attraverso questo ‘esperimento tecnico-sociale’, è stato possibile esaminare dati, aggregarli e compararli con studi sulla salute e valutare la variazione di inquinamento acustico diurno e notturno. Successivamente i dati raccolti a Placa del Sol sono stati comparati con quelli delle altre zone di Barcellona rendendo i cittadini consapevoli del fatto che sebbene il Comune stesse già monitorando i livelli di rumorosità di Placa del Sol, non li rendeva pubblici e non li utilizzava oggettivamente per intervenire nel merito.
Dobbiamo imparare a considerare il contesto dal quale i dati vengono estrapolati
Sembra una banalità ma non lo è affatto, raccogliere dati senza comprendere il contesto dal quale essi provengono rende gli stessi dati inefficaci per il raggiungimento di alcuni scopi. E’ proprio il contesto a rendere i dati “Thick”, vale a dire “densi, spessi”, e la comprensione del contesto a differenziarli dai Big Data, raccolti dai data point, dati che senza reinterpretazione possono dire tanto e nulla allo stesso tempo. L’esempio di Placa del Sol ci fa comprendere come non è tanto la tipologia di dati immagazzinati a fare la differenza ma i metodi utilizzati per raccoglierli e immagazzinarli, l’approfondimento del contesto.
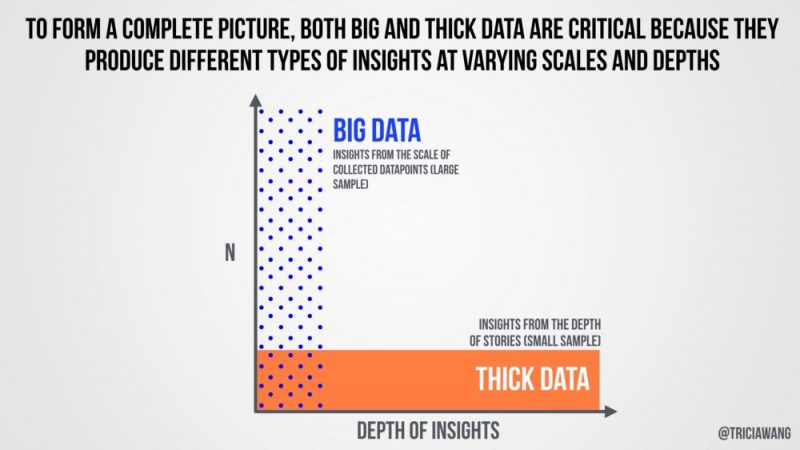
Come Nokia non fu in grado di interpretare i dati di cui disponeva
A tal proposito è interessante l’intervento al TED TALK di Tricia Wang, co-fondatrice di Sudden Compass, una società di consulenza che aiuta le aziende a stare al passo con le esigenze dei clienti, analizzando i big data attraverso “intuizioni umane”, vale a dire l’analisi di tutti quei fattori che possono sfuggire alle macchine: “Perché così tante aziende prendono le decisioni sbagliate, anche quando hanno accesso a quantità di dati mai viste prima? Disporre di un’enorme mole di dati è inutile se non si sa interpretarli nel modo adeguato. Investire nei big data è facile ma usarli è una sfida. Più del 73% dei progetti che impiegano i big data non sono redditizi e molti dirigenti mi dicono: “Stiamo avendo lo stesso problema, abbiamo investito in sistemi di big data ma i nostri dipendenti non prendono le decisioni migliori e non hanno neanche avuto idee innovative”.
Tricia, che ha lavorato anche nel settore ricerca della Nokia, spiega così la propria esperienza e perché ritiene che il non saper interpretare al meglio quei dati abbia causato il crollo del marchio che, prima di Apple, dominava il settore della telefonia: “Facevo ricerche sul campo, passando giorno e notte negli internet point con i giovani cinesi, per capire come usavano i giochi e i telefonini e come li impiegavano per spostarsi dalla campagna alle città. Con le testimonianze che raccoglievo, cominciavo a vedere che un grosso cambiamento stava per avvenire tra i cinesi dal reddito basso. Anche se erano circondati da pubblicità di prodotti di lusso come toilette eleganti – chi non ne vorrebbe una? – appartamenti, automobili, parlando con loro ho scoperto che le pubblicità che interessavano di più erano quelle degli iPhone, che promettevano l’entrata nella nuova vita high-tech. Vivendo con loro nelle periferie urbane, vedevo persone che investivano metà dei loro redditi per comprare un cellulare, e c’erano sempre più “shanzhai”, ovvero versioni meno care degli iPhone o altri telefoni. Erano molto facili da usare e facevano il loro lavoro. Dopo anni vissuti con loro, facendo tutto quello che loro facevano, ho iniziato a mettere insieme tutti questi dati, dalle cose che sembravano strane, come vendere i fagottini di mele, alle cose che erano più ovvie, come registrare i costi del loro traffico telefonico. Sono riuscita a creare un’immagine più olistica di ciò che stava succedendo. Ho cominciato a capire che anche i cinesi più poveri volevano uno smartphone e che avrebbero fatto di tutto per averne uno. Gli iPhone erano appena usciti, nel 2009, e gli Android iniziavano a somigliare agli iPhone. Molte persone intelligenti e realistiche dicevano: “Questi smartphone (gli iPhone, ndr) sono solo una moda. Chi vorrebbe portarsi in giro queste cose pesanti con le batterie che si scaricano subito e che si rompono appena cadono?”. Ma io avevo molti dati, mi fidavo delle mie intuizioni, ed ero entusiasta di condividerle con la Nokia che, tuttavia, non era convinta perché non disponevo della stessa mole di informazioni dei big data. Mi dissero: “Abbiamo milioni di dati, e non ci sono indicazioni che la gente comprerà smartphone. Il tuo insieme di dati è troppo debole per poterlo prendere sul serio”. Risposi: “Nokia, avete ragione. È ovvio che non lo vediate, perché fate sondaggi pensando che la gente non sappia cosa sia uno smartphone, quindi non ricevete dati sulle persone che vorranno uno smartphone tra due anni. I vostri sondaggi e metodi sono stati creati per rinnovare un modello di business esistente e io sto analizzando dinamiche umane emergenti non ancora accadute. Stiamo guardando fuori dalle dinamiche del mercato per superarle”. Sapete cosa è successo alla Nokia? Il business è precipitato. Era inimmaginabile.
Come i Thick data cambieranno la nostra vita
L’autonomia dei cittadini nel disporre, analizzare e confrontare dati, ha fatto si che a Placa del Sol quello che era un problema del “singolo” si è configurato in una questione collettiva. Ampliando la nostra veduta, pensando ad esempio al marketing, proprio come nel caso di Nokia, i Big Data ci dicono essenzialmente “chi”, “come”, “quando” e “dove”, ma difficilmente sanno spiegarci il “perché”. Non possiamo sfruttare solo numeri e algoritmi per comprendere, ad esempio, il comportamento di un cliente a 360 gradi, questo perché vi sono fattori imprevedibili che possono determinare una scelta di acquisto, primo fra tutti il fattore emotivo e razionale (una buona fetta di acquirenti non è interessata a ‘quello che vogliono tutti’).
“I thick data colmano le lacune nell’analisi dei big data”, scriveva Mary Shacklett su Tech Republic il 6 gennaio 2015. Nulla di più vero. Ancora più precisa è la descrizione di Mike Cassidy, nel suo articolo “Big data is yielding to thick data and that’s a good thing” pubblicato il 3 maggio 2014 su BloomReach: “I dati spessi rappresentano semplicemente l’idea che i numeri da soli non bastano. Per comprendere veramente i dati, è spesso necessario considerare cose come le emozioni umane, che raramente possono essere previste con accuratezza”.
In definitiva i Thick Data (dati qualitativi) sono l’opposto dei Big Data (dati quantitativi su larga scala che coinvolgono nuove tecnologie intorno all’acquisizione, archiviazione e analisi). Affinché i Big Data possano essere analizzabili, bisogna applicare la normalizzazione, la standardizzazione, la definizione e il clustering a tutti i processi che estrapolano dati senza tener conto del contesto. Questo non significa che i Thick data debbano sostituire i Big data, ma semplicemente si completano a vicenda e questo ci offre un potenziale davvero notevole: coniugare qualità e quantità dando origine ad un match che ci permetterà di predire meglio gli eventi futuri aggiungendo al “chi”, “come”, “dove” e “quando” anche un “perché”.


